Introduction to the Nullstellensatz/Linear Algebra Method
We have spent a lot of time discussing how to generate objects, but in order for us to generate them they must exist! This idea of showing existence versus non-existence is central to the computational complexity classes of NP and coNP: the difference is whether you use an existential quantifier or a universal quantifier. So, nonexistence problems can be phrased as “All objects do not have this property” and are not suited well to proof by certificate. We can demonstrate existence by finding and presenting the object, but nonexistence is harder to prove.
Today, we discuss Computing Infeasibility Certificates for Combinatorial Problems through Hilbert’s Nullstellensatz by Jesús A. De Loera, Jon Lee, Peter N. Malkin, and Susan Margulies, where they develop what I will call the Nullstellensatz/Linear Algebra Method, or NulLA for short. Their method starts with a set of polynomials whose common roots correspond to the goal object and they build a Nullstellensatz certificate that demonstrates that a set of polynomials have no common root. The certificate is built by solving a set of linear equations. This method is greatly improved by using symmetry to reduce the size of the linear system. The authors’ main idea is to use these certificates to prove certain graphs are not 3-colorable, but I believe this can be used to prove nonexistence of combinatorial objects.
Read the rest of this entry »

 , we will discuss the power set
, we will discuss the power set 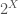 of all subsets of
of all subsets of 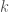 -subsets
-subsets 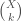 , the
, the 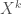 , and the
, and the  . There are multiple ways to store a given subset, tuple, or permutation, but what is more important is how to store a list of information over the entire collection of these objects. My favorite method is to use a ranking function, which assigns each object an integer which I can use as an array position. Then, an unranking function will invert this process.
. There are multiple ways to store a given subset, tuple, or permutation, but what is more important is how to store a list of information over the entire collection of these objects. My favorite method is to use a ranking function, which assigns each object an integer which I can use as an array position. Then, an unranking function will invert this process.