Introduction to Canonical Deletion
by Derrick Stolee
Today, I discuss McKay’s isomorph-free generation technique, commonly called canonical deletion, or canonical construction path. The technique guarantees that every unlabeled object of a desired property will be visited exactly once. The word visited means that a labeled object in the isomorphism class is generated and tested for the given property and possibly used to extend to other objects. Also, objects that do not satisfy the property are visited at most once because we may be able to use pruning to avoid generating objects that do not lead to solutions.
The canonical deletion technique is so called from its use of reversing the augmentation process in order to guarantee there is exactly one path of augmentations from a base object to every unlabeled object. Essentially, a deletion function is defined that selects a part of the combinatorial object to remove, and this function is invariant up to isomorphism. Then, when augmenting an object this augmentation is compared to the canonical deletion of the resulting object to check if this is the “correct” way to build the larger object. If not, the augmentation is rejected and the larger object is not visited. By following the canonical deletion from any unlabeled object, we can reconstruct the unique sequence of augmentations that leads from a base object to that unlabeled object. Further, this process is entirely local: it depends only on the current object and current position within the search tree. This allows the process to be effective even when parallelizing across computation nodes without needing any communication between nodes, unlike some other isomorph-free generation methods which require keeping a list of previously visited objects. Along the way, we will use a consistent example of generating a certain class of graphs to make the discussion more concrete.
Disclaimer: This post was adapted from a background chapter of my Ph.D. thesis. It was written to provide a different perspective on the very abstract nature of the generation algorithm. There are some very subtle points that can be missed easily in McKay’s original paper.
Objects, Augmentations, and Deletions
Suppose we are searching for combinatorial objects from a family 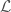


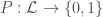


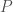


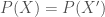

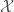


Example: Let 
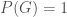

We require a set 

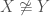
For a labeled object 
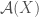
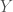
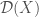
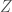
There must be a bijection 
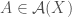


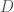
We shall consider our objects as being built up, so the set of augmented objects 


Figure 1. Augmentations
Example: Suppose we wish to enumerate all connected graphs of order 
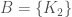
Every vertex augmentation is given by specifying the neighborhood of the new vertex in the graph, so every augmentation is a pair 

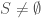





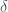
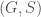




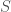

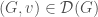


Figure 2. Vertex augmentations 

These definitions of augmentations and deletions are based on labeled objects. In order to generate at most one labeled representative of every unlabeled object, we must consider what isomorphism means in this context.
Augmentations and Orbits
For isomorphism concerns, we shall assume that for an unlabeled object 
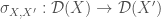
- For all
, the object
such that
and object
such that
are isomorphic (
).
- For all
, the object
and the object
are isomorphic (
This allows us to define the augmented and deleted objects 

Example: If two graphs, 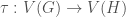

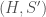



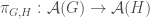
Now, we wish to remove isomorphic duplicates, so the most natural first step is to remove duplicate augmentations. That is, if we are augmenting an object 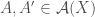

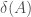

Example: When augmenting a graph 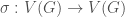
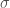

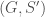


It is an unfortunate fact that these local orbit calculations are not enough to guarantee that we shall not create duplicate objects. There are several reasons, including:
- Augmentations that are not in orbit can create isomorphic objects. See Figure 3.a, where two single-vertex neighborhoods are not in orbit but augmenting by either creates the same unlabeled graph. Figure 3.b shows this ambiguity in the reverse direction, where two deletions from different orbits result in the same graph.
- There may be two internally disjoint sequences of non-isomorphic augmentations which generate the same unlabeled object. Figure 4 shows two different sequences of three vertex augmentations starting from

Figure 3. Examples of orbit complications.

Figure 4. Two disjoint augmentations to the same graph.
These concerns demonstrate that a “bottom up” approach to avoiding duplicate graphs is not satisfactory. The canonical deletion technique avoids this issue by reversing the process: it makes sure that every unlabeled graph has a unique sequence of deletions that leads to a base object.
Canonical Labelings
In order to avoid the previously mentioned pitfalls that lead to multiple labeled representatives of an isomorphism class being visited in the search, we must utilize a powerful tool that allows us to compute invariants.
For a family of labeled objects 




In this sense, the labeling function 

Example: When the family of labeled objects 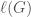

nauty library was designed to efficiently compute canonical labelings. The algorithm defines the map nauty algorithm.
Canonical Deletions
Finally, we are able to describe the canonical deletion. This deletion is the most fundamental concern to this search technique. A canonical deletion function is a map 



Example: When building graphs by vertex augmentations, a graph 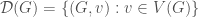

WARNING: When restricting to connected graphs, we must be sure that the deletion we select leads to a connected graph. Therefore, the canonical deletion should select the smallest-index vertex that is not a cut vertex.
Given access to a canonical deletion, we can now describe the full canonical deletion algorithm.
CanonicalDeletion(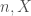
if Prune(
// There are no solutions “above” this object.
return
if IsSolution(
// This object is a solution.
Output
ifOrder(
// This object is too large to augment.
return
for all augmentations
// Convert the augmentation into a deletion.

// Find the labeled object that corresponds to that deletion.

// Compute that object’s canonical deletion.
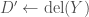
// Test if the current augmentation corresponds to that canonical deletion.
if
// Visit the object
call CanonicalDeletion(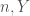
return
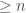

The reason this algorithm is correct is due to the fact that following the canonical deletions 
Given a labeled object 

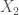

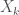
- The first object
- For
,
. That is, the canonical deletion from
corresponds to an augmentation from
.
- The last object
.
Thus, the objects that are visited by the CanonicalDeletion algorithm are exactly those with deletion sequences 

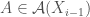
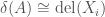
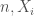
It is very important that we make the distinction that for an augmentation 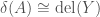
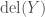
Figure 5 presents an example of the complicated network that may exist between the augmentations and deletions of combinatorial objects, but that the canonical deletion selects a subtree structure to this network. Specifically, the canonical deletions are presented as thick lines and there is exactly one path from a given object to the base object.

Figure 5. A network of unlabeled objects with augmentations/deletions.
Example: The algorithm GraphCanonicalDeletion is a specific implementation of the canonical deletion algorithm for generating graphs by vertex augmentations. It restricts to graphs with maximum degree four and chromatic number at most three.
GraphCanonicalDeletion(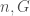
if 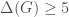
// There are no solutions with
return
if 

// This graph is a solution.
Output
return
if
// This graph is too big to extend
return
for all orbits 
Let 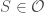
// Create the augmented graph.
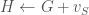
Compute that object’s canonical deletion.

// Test if the current augmentation corresponds to that canonical deletion.
if 
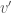
Visit the graph
call GraphCanonicalDeletion(
return



Efficiency Considerations
Based on my experience in creating specific implementations of the canonical deletion algorithm, I contribute a few suggested methods for writing more efficient software.
Deletion by filtering
Calling nauty is an expensive computation, so it should be avoided whenever possible. However, we cannot exactly compute the canonical deletion without it, but we can sometimes determine that our current augmentation does not correspond to the canonical deletion without using nauty. Therefore, I instead create a method IsCanonical(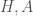
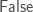
- Start with an easy invariant metric, such as minimum degree of a vertex. This restricts the possible deletions very quickly in most cases.
- Define a sequence of more complicated invariant metrics, such as minimizing the sum of the squares of all the neighbor degrees. Such invariants can remove even more choices without being overly costly to compute.
- If all previous restrictions on the choice of canonical deletion did not prove that the current augmentation is not canonical, we have two options. We can check if the list of feasible deletions that fit the previous invariants has size exactly one. If so, then we know without a doubt that this deletion is canonical. Otherwise, we need to select a deletion using a canonical labeling and then check if the current augmentation is in orbit with that canonical deletion. Both of these checks can be done using a single call to
nauty.
Reduced augmentation count
In the previous suggestion, we restricted the choice of canonical deletion to a simple invariant minimization, such as minimizing the vertex degree. Making such a restriction as part of your canonical deletion can reduce the number of augmentations you attempt, for instance by only augmenting vertices of degree at most 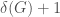
Pruning in deletion
Again, since calling nauty is probably the most computationally expensive subroutine in this algorithm, it may be useful to check if the augmented graph should be pruned even before finishing the canonical deletion. This may depend on how complicated your Prune(
Skipping augmentation orbit calculation
For some augmentations, it may be difficult to completely compute the orbits of augmentations. Vertex augmentations is such an example, because there are many possible neighborhood sets. It may be more beneficial to ignore the automorphism calculation and instead just attempt every augmentation. For every successful augmentation, store a canonical labeling of the augmented object. Then, the objects generated from the current object are visited if and only if the augmentation corresponds to the canonical deletion and that augmented object is not isomorphic to any previous augmentation. By storing a list of visited objects at a given node, we are using the canonical labelings locally, which can be very efficient. See McKay’s original paper for more details about this strategy.
Experiment with the augmentation step
Depending on what type of objects you are generating, there may be something special about their structure that you can exploit in the augmentation step. Observe that in a triangle-free graph every vertex neighborhood is an independent set. McKay provides an example of generating triangle-free graphs by making the vertex augmentations only use independent sets. More radical experimentation of augmentations will be discussed in later posts.
References
S. G. Hartke and A. Radcliffe. Mckay’s canonical graph labeling algorithm. In Communicating Mathematics, 479, 99–111. American Mathematical Society, 2009.
B. D. McKay. Isomorph-free exhaustive generation. J. Algorithms, 26(2):306–324, 1998.
B. D. McKay. nauty user’s guide (version 2.4). Dept. Computer Science, Austral. Nat. Univ., 2006.

Great post.
There are some $-signs floating around somewhere, which was not converted to LaTeX, I think you should be able to find them all by just search for “$”.
Thanks for the heads-up. I thought I caught them all, but I’ll be sure to check more carefully next time.