Best Practices for Scientific Computing
The following tweet found its way into my Twitter newsfeed.
Important paper: Best Practices for Scientific Computing http://t.co/GJc0fviciJ
— Mike Loukides (@mikeloukides) January 12, 2014
I thought it would be appropriate to take the advice found in this article and apply them specifically to computational combinatorics. In particular, they identify and outline eight best practices, which I will discuss individually. Further, during the discussion I will include how I apply (or will apply) these concepts during my own development process. Below, I have simply copied their “Summary of Best Practices”. You can investigate each item in more detail in the original article. I’ll add my own ideas under each main topic.
Caveat: I showed this paper to a software engineer (my wife) and she thought all of these items would be obvious to anyone with even a basic understanding of software engineering. However, as the original paper is written for biologists and this blog is written for mathematicians, I find it appropriate to cover these ideas.
Read the rest of this entry »
 , a clique is a set
, a clique is a set  such that all pairs of vertices in
such that all pairs of vertices in 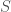 are adjacent in
are adjacent in 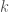 -tuples of vertices, as well. Really, all you need is an object with a
-tuples of vertices, as well. Really, all you need is an object with a 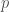 -extremal graphs for
-extremal graphs for  . We’ll start by talking about the mathematics, and at the very end we will go into the concrete piping example. Theoretically, you could skip straight to the code, but you’ll miss out on the fact that the computer is simultaneously discovering and proving a structure theorem for an infinite class of graphs!
. We’ll start by talking about the mathematics, and at the very end we will go into the concrete piping example. Theoretically, you could skip straight to the code, but you’ll miss out on the fact that the computer is simultaneously discovering and proving a structure theorem for an infinite class of graphs!