Ranking and Unranking of Combinations and Permutations
by Derrick Stolee
Now that we’ve discussed a nice standard example of canonical deletion, I want to get into more complicated uses. These techniques use more complicated augmentations and deletions, and hence require a little more delicate description of orbit calculations. In order to get to those, we need to be able to store and manipulate subsets of things. Another way to think of “subsets of things” is combinations, especially when we know the size of the subset.
Given a set 
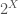
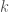
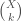
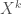

This area has a long history, with several different methods of ranking and unranking the objects competing for dominance in several measures of quality. My favorite measure is “readability” and/or “ease of programming” but definitely “computation speed” is important, too. However, sometimes ranking is fast and unranking is slow, sometimes the ranking and unranking is fixed to a certain order, such as lexicographic order.
Today we’ll talk about several ranking and unranking procedures, and the next post will discuss how to use these ranking/unranking functions to compute orbits of these objects for a graph with symmetry.
Since we will be dealing with actual software implementations of these combinatorial objects, we shall use the following conventions:
.
- For
,
is the
th element of
, for
.
Ranking Subsets
Subsets are some of the easiest objects to rank, since there is a very simple bijection between the subsets of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=fff&fg=444444&s=0&c=20201002)
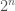
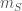

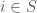
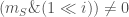
Of course, actually ranking all subsets is not recommended for large
Ranking Tuples
To rank tuples, consider the simplest way to count 
![i \in [k] = \{0,\dots,k-1\}](https://s0.wp.com/latex.php?latex=i+%5Cin+%5Bk%5D+%3D+%5C%7B0%2C%5Cdots%2Ck-1%5C%7D&bg=fff&fg=444444&s=0&c=20201002)
![{\mathbf x} \in [n]^k](https://s0.wp.com/latex.php?latex=%7B%5Cmathbf+x%7D+%5Cin+%5Bn%5D%5Ek&bg=fff&fg=444444&s=0&c=20201002)

In the special case that 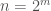
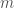
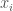
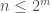

Ranking Combinations
Lexicographic Order
The most natural way to order combinations of 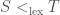
![S[i] = T[i]](https://s0.wp.com/latex.php?latex=S%5Bi%5D+%3D+T%5Bi%5D&bg=fff&fg=444444&s=0&c=20201002)
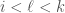
![S[\ell] < T[\ell]](https://s0.wp.com/latex.php?latex=S%5B%5Cell%5D+%3C+T%5B%5Cell%5D&bg=fff&fg=444444&s=0&c=20201002)

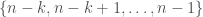


This ordering provides a natural ranking procedure:
![{\mathrm{rank}}_{\text{lex}}(S) = \sum_{i=0}^{k-1} \sum_{v=S[i-1]+1}^{S[i]-1}\binom{n-(v+1)}{k-(i+1)}](https://s0.wp.com/latex.php?latex=%7B%5Cmathrm%7Brank%7D%7D_%7B%5Ctext%7Blex%7D%7D%28S%29+%3D+%5Csum_%7Bi%3D0%7D%5E%7Bk-1%7D+%5Csum_%7Bv%3DS%5Bi-1%5D%2B1%7D%5E%7BS%5Bi%5D-1%7D%5Cbinom%7Bn-%28v%2B1%29%7D%7Bk-%28i%2B1%29%7D&bg=fff&fg=444444&s=0&c=20201002)
The idea of this ranking is that we go through all of the positions 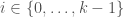


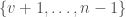
unranklex():
![S \leftarrow [k]](https://s0.wp.com/latex.php?latex=S+%5Cleftarrow+%5Bk%5D&bg=fff&fg=444444&s=0&c=20201002)

while
:
if
:
else
![S[i] \leftarrow t](https://s0.wp.com/latex.php?latex=S%5Bi%5D+%5Cleftarrow+t&bg=fff&fg=444444&s=0&c=20201002)

return
This ranking function is unfortunate that it requires the nested sums (and the binomial requires a loop to calculate, as well). By changing the order slightly, we can improve performance.
Co-Lex Order
Using the co-lexicographic ordering of the combinations can simplify a few things. First, the dependence on 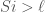
To rank a set 
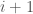
![[\ell]](https://s0.wp.com/latex.php?latex=%5B%5Cell%5D&bg=fff&fg=444444&s=0&c=20201002)
![S[i+1], \dots, S[k-1]](https://s0.wp.com/latex.php?latex=S%5Bi%2B1%5D%2C+%5Cdots%2C+S%5Bk-1%5D&bg=fff&fg=444444&s=0&c=20201002)
![{\mathrm{rank}}_{\text{co-lex}}(S) = \sum_{i=0}^{k-1} \binom{S[i]}{i+1}.](https://s0.wp.com/latex.php?latex=%7B%5Cmathrm%7Brank%7D%7D_%7B%5Ctext%7Bco-lex%7D%7D%28S%29+%3D+%5Csum_%7Bi%3D0%7D%5E%7Bk-1%7D+%5Cbinom%7BS%5Bi%5D%7D%7Bi%2B1%7D.&bg=fff&fg=444444&s=0&c=20201002)
To un-rank an index
unrankco-lex():
while
:
while
:

![S[i] \leftarrow \ell - 1](https://s0.wp.com/latex.php?latex=S%5Bi%5D+%5Cleftarrow+%5Cell+-+1&bg=fff&fg=444444&s=0&c=20201002)
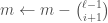
return
Ranking Permutations
You know what? I started this post two weeks ago and delayed writing because I’ve never ranked or unranked a permutation. Apparently, it’s not a simple task. See the references below by Er and Myrvold & Ruskey who present a very detailed bibliography on the techniques here. Also, see Glenn Tesler’s presentation on ranking, unranking, and finding sequential permutations.
Signed Objects
A signed object is usually a pairing of a standard (unsigned) object (such as the objects above) and associating a positive or negative value to each element or position in that object. For example, a signed permutation is really a pair 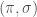
![\pi : [n]\to[n]](https://s0.wp.com/latex.php?latex=%5Cpi+%3A+%5Bn%5D%5Cto%5Bn%5D&bg=fff&fg=444444&s=0&c=20201002)
![\sigma : [n] \to \{+1,-1\}](https://s0.wp.com/latex.php?latex=%5Csigma+%3A+%5Bn%5D+%5Cto+%5C%7B%2B1%2C-1%5C%7D&bg=fff&fg=444444&s=0&c=20201002)
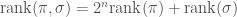

References
J. Arndt, Matters Computational: Ideas, Algorithms, Source Code. Available on the FXT page.
T. Johnston, Sorting Signed Permutations Using Cut-And-Paste Operations, UNL Honors Thesis (2009).
M. C. Er, Lexicographic Enumeration, Ranking, and Unranking of Permutations of 
W. Myrvold, F. Ruskey, Ranking and Unranking Permutations in Linear Time, Information Processing Letters (2000).

Thank you so much for this nice article. One minor comment:
In unrankco-lex, right after assigning S[i] there is a line missing that should decrease the variable m by binomial(l-1,i+1).
Thanks for the tip! Yes, I did accidentally leave that out. It is in now.
Hey Derrick, can you tell me this in a simple way? For example I have a way to calculate index (rank) of Permutations without repetitions 5 from 10 elements in the following way:
first index: (1 2 3 4 5) == 0*9!/5! + 0*8!/5! + 0*7!/5! + 0*6!/5! + 0*5!/5!
== 0*3024 + 0*336 + 0*42 + 0*6 + 0*1
== 0
last index: (10 9 8 7 6) == 9*3024 + 8*336 + 7*42 + 6*6 + 5*1
== 30239
Question:
Do you have a way to do the same but with combinations without repetitions? Same elements 5 from 10. First index is 0 and last 250
Thanks!
If you use the co-lex order, then the result will be very similar, but you will use binomial coefficients instead of your n!/r! coefficients. (Also, be sure to sort your combinations!) Also, it helps if your values start at 0, not 1 (if you start at 1, then you will want to replace all instances of “ ” with “
” with “ ” in the formula below:
” in the formula below:
Index of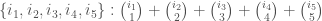 .
.
Thank you for this excellent article. It has helped me immensely.
When implementing unrank_colex in C++, I had to adjust the second while loop condition as follows
while (n_choose_k(l, i + 1) = 0)
It seems like, within the inner while loop, i can at times become less than zero…
Please pardon my comment if such an implementation is already implied by your notation. (I’m fairly new to combinatorial algorithms.)
I think my initial attempt to write the condition was stripped by wordpress formatting
I added i >= 0 as a condition with && so the final inner while loop condition is
while (n_choose_k(l, i + 1) = 0)
Eh, sorry for the above comment spam. I’m seeing other strange issues now, so the issue is likeliest with my code.
Please feel free to nuke the above comments, apologies for the interruption.
Thanks again for the post though, it’s great stuff.
Excellent article. The unrank lex algorithm was new to me, works like a charm!